The Amazon Kinesis Event
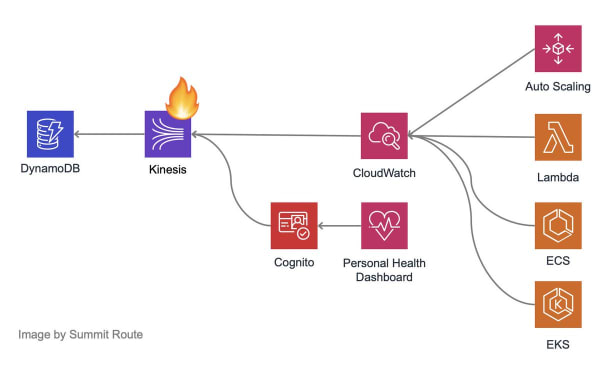 (A hypothetical dependency graph that led to a systemic failure in AWS us-east-1 from @0xdabbad00)
(A hypothetical dependency graph that led to a systemic failure in AWS us-east-1 from @0xdabbad00)
Like many, I was personally affected by the AWS outage last week. I was on-call, and was paged for a couple of reasons. While I was paged, I owe a lot to the infrastructure team I work with. They managed all of the issues I was paged for, and outside of a few spurious pages, I was mostly insulated from the issue.
AWS wrote a post mortem, but this analysis is an interesting take.
Forget the hot takes. Here’s the cold reality: The Kinesis Incident is not a story of independent, random error. It’s not a one-off event that we can put behind us with a config update or an architectural choice.
It’s a story of systematic failure.
We will spend the next decade talking about systemic failure, the unknown unknown. Yet, It’s so elusive and slippery in our brains. It’s like thinking about recursive concepts, it can hurt your brain.
This won’t get easier for AWS either, as the author points out, two things that compound this issue.
What’s the systematic failure here? Two-pizza teams. “ Two is better than zero.” A “ worse is better ” product strategy that prioritizes shipping new features over cross-functional collaboration. These are the principles that helped AWS eat the cloud. They create services highly resilient to independent failures. But it’s not clear that they are a recipe for systematic resilience across all of AWS. And over time, while errors in core services become less likely, the probability builds that a single error in a core service will have snowballing, Jenga-collapsing implications.
And…
The edges in AWS’s internal service graph are increasing at a geometric rate as new higher-level services appear, often directly consuming core services from Kinesis, DynamoDB, and so on.
Who doesn’t want a customer focus or re-use of internal services? That sounds like an efficient organization. One that tries to align engineering with value delivery to the customer. If doing that puts you at a greater risk of systemic failure, we are in for an eventful decade.
If you, like me, are a little bit concerned about this, I would highly recommend reading this issue of ACM Queue: “Revealing the Critical Role of Human Performance in Software” Put together by David D. Woods and John Allspaw.
The first paragraph:
People are the unique source of adaptive capacity essential to incident response in modern Internet-facing software systems. The collection of articles in this issue of acm queue seeks to explore the forms of human performance that make modern business-critical systems robust and resilient despite their scale and complexity.
It’s a weighty tome, but the essence for me is, as the edges increase in our modern world (software or otherwise) complexity and systemic risk will also grow. Therefore, we must grow the adaptive capacity of every individual to manage the complexity and interconnectedness of modern systems.
While I think we can do both, the true risk is that we we don’t focus on human capacity as much as we focus on capturing market share.